ClusterTop
February 2, 2016
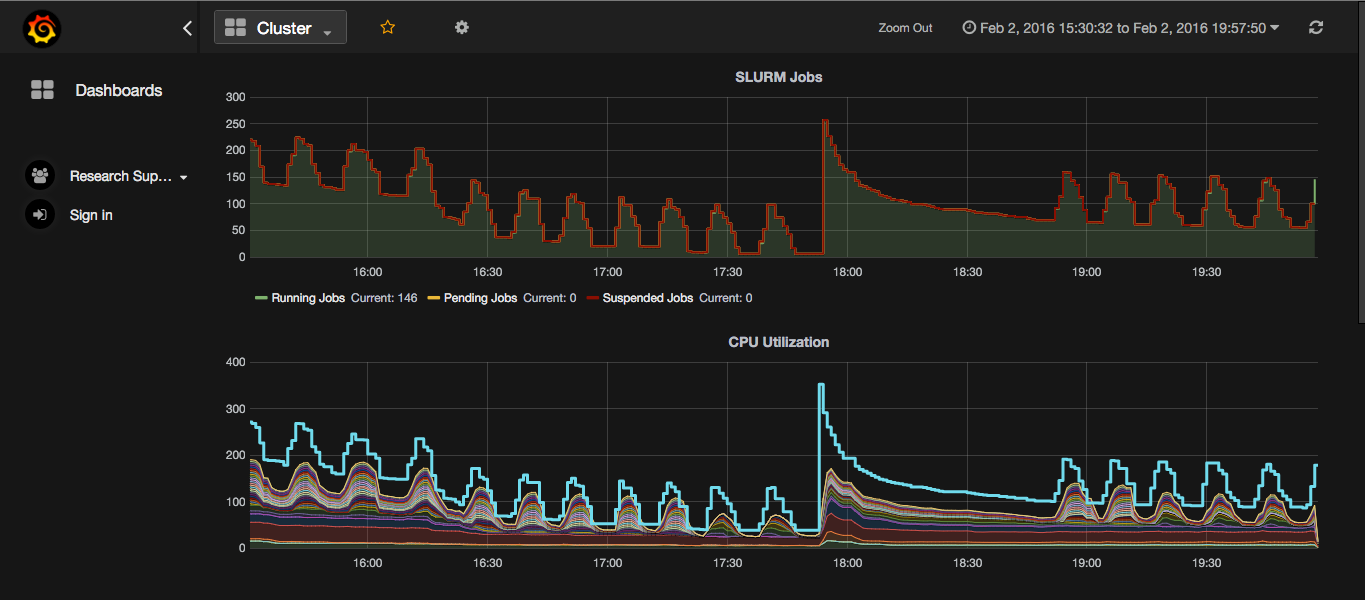
I work for Research Computing at RIT. When I first came on board I was tasked with extracting data from our monitoring solution, Zabbix, and pushing into graphite. So I wrote Clustertop. Clustertop works by periodically polling zabbix for data and then pushing that data somewhere else using plugins. Its completely configured using a simple config file which looks something like this.
[main]
zabbix_host=http://some.host.some.where/zabbix
zabbix_user=guest
zabbix_pass=
item_keys=system.cpu.load[|avg1],vm.memory.size.available
update_interval=15
hosts=interlagos-01,interlagos-02,overkill
poller=clustertop.poller:GraphitePoller
[special:ion]
slurm.jobs.running=system.run[squeue -t R --noheader | wc -l]
slurm.jobs.pending=system.run[squeue -t PD --noheader | wc -l]
slurm.jobs.suspended=system.run[squeue -t S --noheader | wc -l]
[graphite]
host = localhost
port = 2004
It uses a simple ini file. You can configure how to talk to zabbix, as well as
what keys/hosts to grab data for. The poller option allows for the usage of
customer pollers. In the above example the GraphitePoller is used. Below that
there is another example of how to specify what data to grab from zabbix.
[special:<hostname>] blocks allow you to do one off checks for a specific host.
In the above case it is used to get special data off of a cluster head node.
The rest of the config can be used to configure the custom pollers. Here
the graphite poller is told how to contact the graphite server.
Technology
Clustertop is built on python 2.7 and its dependencies are listed below.
By default clustertop only comes with 2 different pollers. The first is the
default poller, clustertop.poller:Poller. This poller prints out the data
it grabbed from zabbix. It is useful for debugging, and is also the base on
which all custom pollers are built. The other builtin poller is clustertop.poller:GraphitePoller. This is also a pretty simple poller, it just pushes data into graphite.
Running it
Clustertop has two commands, check and run. check does the same thing as run, except instead of executing in a loop, it does it once and exists. Useful for debugging and verifying the configuration.
$> clustertop check --config /etc/clustertop
$> clustertop run --config /etc/clustertop